In this post I will show you how to use the Azure command line utility, AzCopy in combination with Azure WebJobs to build your own scheduled Azure Storage backup utility. You can get the source for this blog post on GitHub here, AzCopyBackup
Credits
Before I start here I have to call out Pranav Rastogi who was a HUGE help to me through this process of me figuring out how to use AzCopy with WebJobs. There is not a whole lot of prior art out there for WebJobs and there is exactly zero (before now) on how to combine the two to make a service to automatically backup your Azure Storage accounts. Pranav was awesome and this blog post would not be possible with out his help.
What is AzCopy?
If you follow Azure you may have heard of AzCopy. This tool was released not so long ago and is a very handy command-line utility which can be used to backup blobs, tables and files stored in Azure. One of the absolute best features of AzCopy is that it copies Azure Storage objects asynchronously server-to-server, meaning that you can run AzCopy sitting in an airplane using crappy airplane WiFi and it will copy your stuff without having to download storage objects locally and then push it back up to the cloud. I really love this tool. If I had one nit to pick, it would be I wished this was released as a DLL and was more interactive with the process that was hosting it; I’ll talk about why a bit later. That said, it’s simple to use. For instance. If I wanted to copy everything from one Container to another recursively (/S) going through everything you would do this in a batch file.
AzCopy /source:https://mystorageacct1.blob.core.windows.net/mycontainer/ /dest:https://mystorageacct2.blob.core.windows.net/mycontainer/ /sourcekey:[sourcekey] /destkey:[destkey] /S
Getting started
For this blog post I’m going to create 4 different projects all inside a single Visual Studio solution. Here they are below.
- A Website in Azure Websites to host the WebJobs.
- A scheduled WebJob to queue up a full backup on two Containers.
- A scheduled WebJob to queue up incremental backups on the same Containers.
- A WebJob that reads from that same queue and executes AzCopy to do the work.
Logical Model
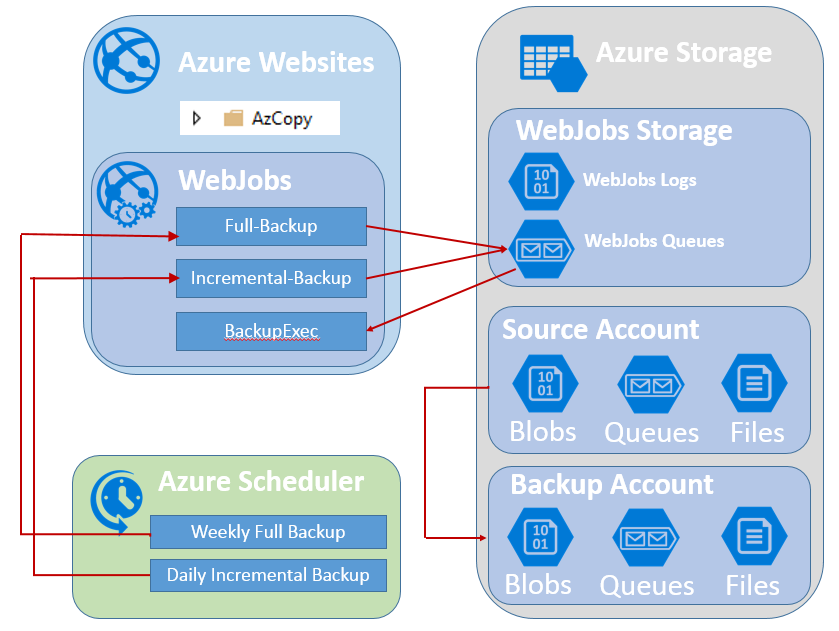
Above you can get an idea of the logical items in this solution. Azure Websites is the host for both the WebJobs and is also where we deploy AzCopy to. Azure Storage includes three storage accounts. The source and destination accounts that are in the backup and a third account that is required by WebJobs. Lastly Azure Scheduler is used to schedule the WebJobs to be run.
Create a new Website to host the WebJobs
First, create a new Website in Azure Websites. You can create WebJobs and attach them to an existing Website in Visual Studio. For now let’s create a new website.
Create a WebJobs Storage Account
WebJobs uses its own Azure Storage Account for it’s Dashboard in Kudu. Create a storage account in the portal. Put it in the same region as the host website. You will need to create a unique name for this storage account. Figure out your own name, use it here and remember it because you will need it here again shortly.
WebJobs requires the connection string for this storage account be put in two environment variables, AzureWebJobsDashboard and AzureWebJobsStorage. You can put these in the app.config for the WebJob but since we are going to be creating multiple WebJob projects we will store these as connection strings in the Azure Management Portal of the host website.
Collecting storage account names and keys
Next get the Account Name and Access Key for the new WebJobs storage account.
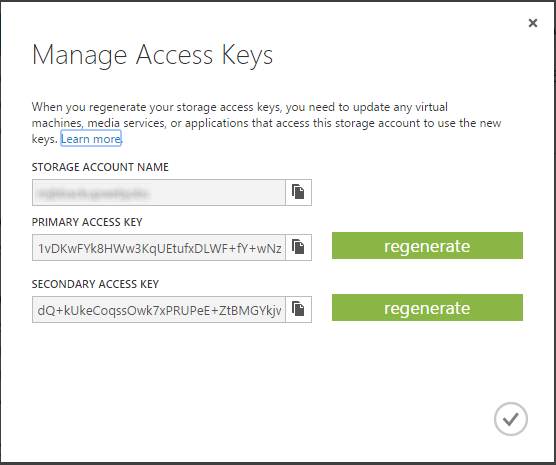
You’re going to be collecting the account name and keys for the source and destination to run the backup on so create a new text file and paste this information into it. Create a storage connection string for both AzureWebJobsDashboard and AzureWebJobsStorage using the connection string format below.

Next, get the storage account name and keys for the storage accounts to copy from and to. For the storage account name and keys, separate them with a semi-colon. Collect all this information and put in a text file in a format that looks like this above, just to keep handy for the next step.
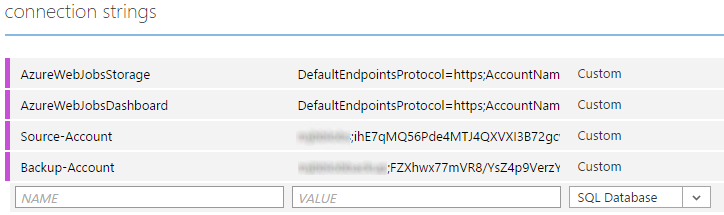
Save Connection Strings in Azure Management Portal
With all of the storage account information, save all these in connection strings in the Azure Management Portal. Navigate to the Configure tab for the host website and scroll down to connection strings. From your text file, cut and paste the contents of the text file into the connection string settings. When you have gone through all the values, your connection strings should look like this.
Create WebJob to do a Full Backup
Next, right click on the Website in Visual Studio and select, Add and New Azure WebJob Project. This WebJob will do a full backup from a container called, “images” and another called, “stuff” from the “Source-Account” to the “Backup-Account”. When it copies the contents it will create new containers in the Backup-Account with the same name as the source, but with a date stamp appended to the name. This will effectively create weekly snapshots of the containers.
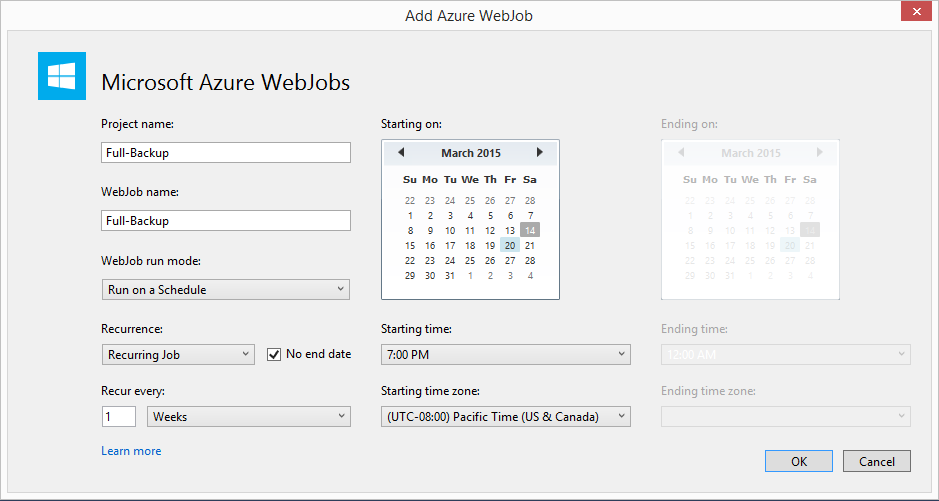
Next, enter the name “Full-Backup” for the WebJob and the schedule information. For this WebJob it will run every Friday night at 7pm Pacific time with no end date.
Coding the Full Backup Job
After the project is created, open References in VS and add System.Configuration as a reference in the project. Next replace the code in Program.cs (this should be open by default when the project is created) with the code shown below.
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; namespace Full_Backup { class Program { static void Main() { var host = new JobHost(); host.Call(typeof(Functions).GetMethod("QueueBackup")); } } }
Next, open the Functions.cs file and replace the code in that file with the code below, including the using statements. The last three are not included by default in a WebJob project.
PS: sorry for the way the source code looks here. Trying to find a better way to do this.
using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; using System; using System.Configuration; using Newtonsoft.Json; namespace Full_Backup { public class Functions { [NoAutomaticTrigger] public static void QueueBackup([Queue("backupqueue")] ICollector<string> message, TextWriter log) { //extract the storage account names and keys string sourceUri, destUri, sourceKey, destKey; GetAcctInfo("Source-Account", "Backup-Account", out sourceUri, out destUri, out sourceKey, out destKey); //create a job name to make it easier to trace this through the WebJob logs. string jobName = "Full Backup"; //Use time stamps to create unique container names for weekly backup string datestamp = DateTime.Today.ToString("yyyyMMdd"); //set backup type either "full" or "incremental" string backup = "full"; //Add the json from CreateJob() to the WebJobs queue, pass in the Container name for each call message.Add(CreateJob(jobName, "images", datestamp, sourceUri, destUri, sourceKey, destKey, backup, log)); message.Add(CreateJob(jobName, "stuff", datestamp, sourceUri, destUri, sourceKey, destKey, backup, log)); } public static void GetAcctInfo(string from, string to, out string sourceUri, out string destUri, out string sourceKey, out string destKey) { //Get the Connection Strings for the Storage Accounts to copy from and to string source = ConfigurationManager.ConnectionStrings[from].ToString(); string dest = ConfigurationManager.ConnectionStrings[to].ToString(); //Split the connection string along the semi-colon string sourceaccount = source.Split(';')[0].ToString(); //write out the URI to the container sourceUri = @"https://" + sourceaccount + @".blob.core.windows.net/"; //and save the account key sourceKey = source.Split(';')[1].ToString(); string destaccount = dest.Split(';')[0].ToString(); destUri = @"https://" + destaccount + @".blob.core.windows.net/"; destKey = dest.Split(';')[1].ToString(); } public static string CreateJob(string job, string container, string datestamp, string sourceUri, string destUri, string sourceKey, string destKey, string backup, TextWriter log) { //Create a Dictionary object, then serialize it to pass to the WebJobs queue Dictionary<string, string> d = new Dictionary<string, string>(); d.Add("job", job + " " + container); d.Add("source", sourceUri + container + @"/"); d.Add("destination", destUri + container + datestamp); d.Add("sourcekey", sourceKey); d.Add("destkey", destKey); d.Add("backup", backup); log.WriteLine("Queued: " + job); return JsonConvert.SerializeObject(d); } } }
Here is what the functions in this class do.
QueueBackup()
This function is called by Main() when the WebJob is executed by the Scheduler. WebJobs includes a built-in queue and log capability. You access them by including them in a function’s signature. I have named the queue in this application “backupqueue”. I have declared the datatype for the message for the queue to be a string and since this function will add more than one message to the queue, add the ICollector interface in front of the string parameter for the [queue]. The built-in log is very helpful when debugging because you cannot attach an on demand or scheduled WebJob to the debugger.
Tip: On Demand and Scheduled WebJobs cannot be attached to the debugger so using the built-in logging feature is very helpful.
The bulk of the work in this function happens on message.Add(). Each call to message.Add() includes a call to CreateJob() and passes in a job name, the container name, the storage account information, the type of backup and the built-in WebJobs logger so it can write a log entry for the backup job that is added to the queue.
GetAcctInfo()
This function gathers the storage account information from the host website’s connection strings we saved earlier. It takes that information and returns 4 output values as output parameters. The URI and key for the storage account to copy from, and the URI and key for the storage account to back it up to. I am hard coding the blob here for the URI. You can change it to table or queue if you want or make it a parameter so the function can queue up a backup job for all three types of storage objects.
Note: Yes I’m using output values. In this instance I found it cleaner and easier to use for this sample than creating a class to store the returned data. If you don’t like it then feel free to change it.
CreateJob()
This function creates a Dictionary object that is built around the command line arguments that AzCopy needs to copy storage accounts from one place to another. This function returns a serialized Json string of the Dictionary object. This Json will be the queue message. Note the date stamp parameter appended to the container name. This ensures unique weekly snapshots of the container being backed up.
Why am I doing this?
By now, you may be thinking, Dude, WTF? Why create a WebJob that puts command-line arguments for AzCopy on a queue? Just run AzCopy!!!
The reason is two-fold. First, AzCopy can only be run one instance at a time by the JobHost in WebJobs. By putting the backup jobs on a queue I can ensure that AzCopy only runs one instance at a time because I can limit how many messages are read and executed at a time in WebJobs (I’ll show you how later).
The second reason is because this pattern allows this app to scale. While I can only run AzCopy one instance at a time per JobHost (one per VM), you are not limited by the number of VM’s that can be run. Since Azure Websites can be scaled to two or more VM’s, this solution can allow AzCopy to run multiple times simultaneously. The example here is only doing a simple back-up of a couple of containers, but by applying this pattern, you can use this code to spawn multiple backup jobs for any number of storage accounts of any size and scale up as you see fit. In addition, by creating smaller units to back up, you can create more of them to run in parallel. You then can control the speed (or the cost) with which the entire set of jobs runs by setting the maximum number of instances to scale.
Create a WebJob to do an Incremental Backup
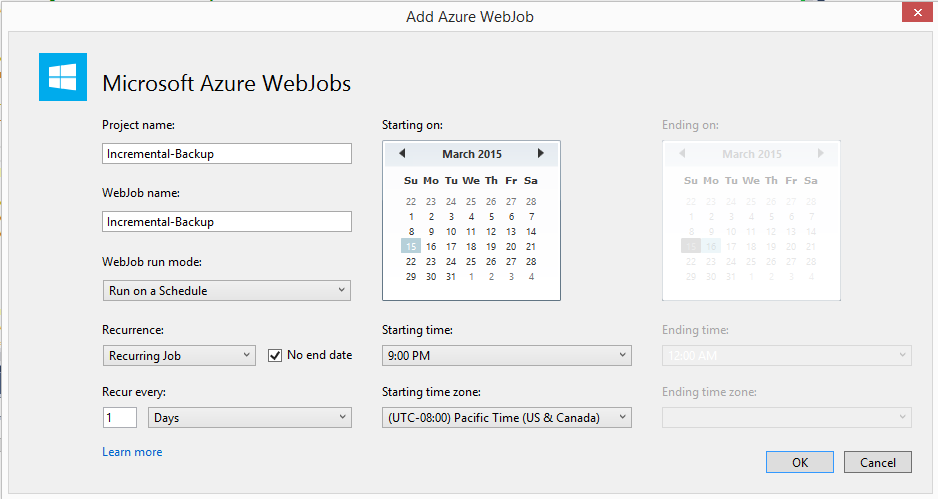
Next repeat the steps to create the Full-Backup WebJob and create a new WebJob “Incremental-Backup” that will queue a message to perform an incremental backup. This one will run Monday through Thursday only. The full backup runs on Friday so we don’t need to run it then. Saturday and Sunday we’ll assume nothing happens so we’ll not run it then either.
Create a new WebJob by right-clicking on the Website project and select Add New WebJob. Next, set the name and schedule for the WebJob.
Next, open the References for the project and select, Add Reference. Then add System.Configuration to the project. Next copy and paste the code here into program.cs
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; namespace Incremental_Backup { class Program { static void Main() { var host = new JobHost(); host.Call(typeof(Functions).GetMethod("QueueBackup")); } } }
Next, open up functions.cs and cut and paste this code, including the using statements.
using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; using System; using System.Configuration; using Newtonsoft.Json; namespace Incremental_Backup { public class Functions { [NoAutomaticTrigger] public static void QueueBackup([Queue("backupqueue")] ICollector<string> message, TextWriter log) { //This job should only run Monday - Thursday. So if it is Friday, Saturday or Sunday exit here. DateTime dt = DateTime.Now; if (dt.DayOfWeek == DayOfWeek.Friday || dt.DayOfWeek == DayOfWeek.Saturday || dt.DayOfWeek == DayOfWeek.Sunday) return; //Get timestamp for last Friday to save incremental backup to the last full backup while (dt.DayOfWeek != DayOfWeek.Friday) dt = dt.AddDays(-1); string datestamp = dt.ToString("yyyyMMdd"); //extract the storage account names and keys string sourceUri, destUri, sourceKey, destKey; GetAcctInfo("Source-Account", "Backup-Account", out sourceUri, out destUri, out sourceKey, out destKey); //create a job name to make it easier to trace this through the WebJob logs. string jobName = "Incremental Backup"; //set backup type either "full" or "incremental" string backup = "incremental"; //Add the json from CreateJob() to the WebJobs queue, pass in the Container name for each call message.Add(CreateJob(jobName, "images", datestamp, sourceUri, destUri, sourceKey, destKey, backup, log)); message.Add(CreateJob(jobName, "stuff", datestamp, sourceUri, destUri, sourceKey, destKey, backup, log)); } public static void GetAcctInfo(string from, string to, out string sourceUri, out string destUri, out string sourceKey, out string destKey) { //Get the Connection Strings for the Storage Accounts to copy from and to string source = ConfigurationManager.ConnectionStrings[from].ToString(); string dest = ConfigurationManager.ConnectionStrings[to].ToString(); //Split the connection string along the semi-colon string sourceaccount = source.Split(';')[0].ToString(); //write out the URI to the container sourceUri = @"https://" + sourceaccount + @".blob.core.windows.net/"; //and save the account key sourceKey = source.Split(';')[1].ToString(); string destaccount = dest.Split(';')[0].ToString(); destUri = @"https://" + destaccount + @".blob.core.windows.net/"; destKey = dest.Split(';')[1].ToString(); } public static string CreateJob(string job, string container, string datestamp, string sourceUri, string destUri, string sourceKey, string destKey, string backup, TextWriter log) { //Create a Dictionary object, then serialize it to pass to the WebJobs queue Dictionary<string, string> d = new Dictionary<string, string>(); d.Add("job", job + " " + container); d.Add("source", sourceUri + container + @"/"); d.Add("destination", destUri + container + datestamp); d.Add("sourcekey", sourceKey); d.Add("destkey", destKey); d.Add("backup", backup); log.WriteLine("Queued: " + job); return JsonConvert.SerializeObject(d); } } }
This code is nearly identical to what we have in Full-Backup, but there are two key differences. I’ll highlight them in this image below.

First, you may have noticed that we said this WebJob would only run Monday – Thursday. However, when we created the WebJob in Visual Studio we set it to run daily. To do the custom schedule I am checking the current date when the job runs and if it falls on Friday, Saturday or Sunday the code calls return and exits out of the routine so the WebJob never queues a backup.
Second, for an incremental copy to work, AzCopy needs something to compare to. Since we have a full backup created every Friday we need to find the previous Friday’s full backup and do the incremental backup to that container.
So we now have three of the four things created for this solution. The last is the WebJob that executes AzCopy. Let’s create that next.
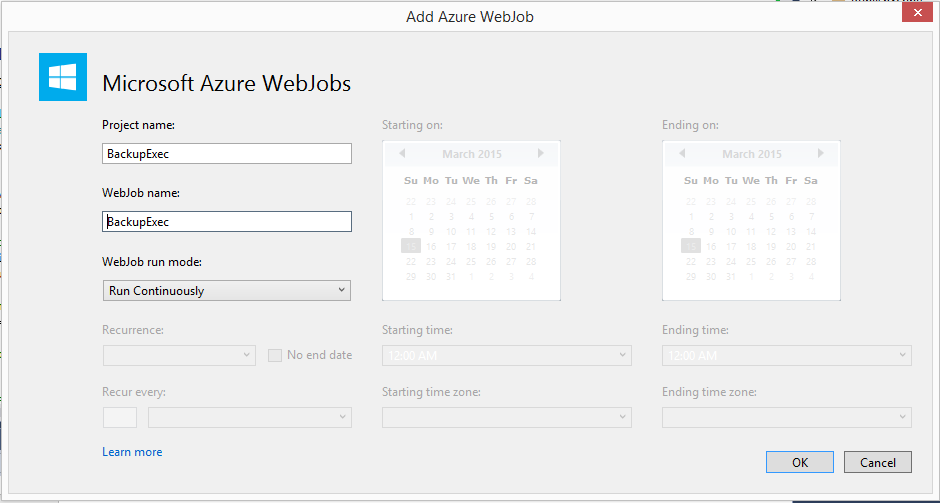
Create the Backup Exec WebJob
Again, right click on the website in Visual Studio and add another WebJob project. We’ll call this one BackupExec. Set the parameters to match what’s here below, most notably, this job is to run continuously.
Coding the Backup Exec WebJob
First, open the program.cs file and replace the code in it with this.
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; namespace BackupExec { class Program { static void Main() { JobHostConfiguration config = new JobHostConfiguration(); //AzCopy cannot be invoked multiple times in the same host //process, so read and process one message at a time config.Queues.BatchSize = 1; var host = new JobHost(config); host.RunAndBlock(); } } }
Normally, a continuously running WebJob will read and process up to 16 messages at one time from a queue. Because we can only run AzCopy once per host process we need to modify this code and set Queues.BatchSize = 1. This ensures that AzCopy is only run once per JobHost process.
As mentioned earlier, to run AzCopy multiple times simultaneously, provision or schedule multiple VM’s or turn on auto-scale.
Note: AzCopy is not a very resource intensive application. You can easily run on a small standard tier VM or even basic tier, if you don’t need auto-scale.
Next open functions.cs and replace the code in that file with this code below.
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using System.Threading.Tasks; using Microsoft.Azure.WebJobs; using System.Diagnostics; using Newtonsoft.Json; namespace BackupExec { public class Functions { // This function will get triggered/executed when a new message is written on the Azure WebJobs Queue called backupqueue public static void ExecuteAzCopy([QueueTrigger("backupqueue")] string message, TextWriter log) { string apptorun = @"D:\home\site\wwwroot\AzCopy\AzCopy.exe"; Dictionary<string, string> d = JsonConvert.DeserializeObject<Dictionary<string, string>>(message); log.WriteLine("Start Backup Job: " + d["job"] + " - " + DateTime.Now.ToString()); StringBuilder arguments = new StringBuilder(); arguments.Append(@"/source:" + d["source"]); arguments.Append(@" /dest:" + d["destination"]); arguments.Append(@" /sourcekey:" + d["sourcekey"]); arguments.Append(@" /destkey:" + d["destkey"]); //backup type: if "incremental" add /XO switch to arguments arguments.Append(@" /S /Y" + ((d["backup"] == "incremental") ? " /XO" : "")); ProcessStartInfo info = new ProcessStartInfo { FileName = apptorun, Arguments = arguments.ToString(), UseShellExecute = false, RedirectStandardInput = true, RedirectStandardError = true, RedirectStandardOutput = true, ErrorDialog = false, CreateNoWindow = true }; Process proc = new Process(); proc.StartInfo = info; proc.Start(); //max wait time, 3 hours = 10800000, 2 hours = 7200000, 1 hour = 3600000 proc.WaitForExit(10800000); string msg = proc.StandardOutput.ReadToEnd(); log.WriteLine(msg); log.WriteLine("Complete Backup Job: " + d["job"] + " - " + DateTime.Now.ToString()); proc = null; } } }
I’ll explain a bit what this code does.
When this WebJob loads this function is waiting for a new item to be written to “backupqueue”. When it does, it begins to execute. The function reads the Json message, deserializes it into a Dictionary object, iterates through the Dictionary and builds a string of command line arguments for AzCopy to use to run the backup.
The function then creates a new ProcessStartInfo object. We need this so AzCopy will execute properly hosted inside a WebJob. Next it creates a new Process and calls Start().
Finally, since AzCopy can sometimes run and run and run and run, we need a way to stop it so we need WaitForExit() so the WebJob will stop after a set period of time. In this example here I am hard coding the value. In a real-world scenario you may want time each backup job and set the value to be longer than what it normally takes to complete.
I also need to point out that sometimes AzCopy stops for no apparent reason. This is the reason why I wish AzCopy was a DLL that allowed me to capture errors and handle them. It’s part of the weakness for running a process inside another. To me it’s worth the trade-off. You may want to go and check the Full-Backup to ensure it ran properly. If it doesn’t, WebJobs has a handy feature allowing you to requeue the message “Replay Function” and kick off the backup job again. Again, if you wanted to get fancy you could probably create a separate process to monitor the WebJob logs and restart the WebJob. That’s a bit out of scope for what is already a really long blog post.
Include AzCopy in the project
Finally, we need to include AzCopy in this project. This project was built using version 3.x. To do this you need to download AzCopy. You can download it from this article on AzCopy. Once you download it, go grab the folder from the location shown in the article and copy it to the website’s project folder in Visual Studio.
Make sure after you copy the AzCopy folder to the project to set Copy to Output Directory to Copy always
So that’s it. Next, build the project and deploy it to Azure.
Let’s Test it
Navigate to the host website in the Azure Management Portal and go to the WebJobs tab. You should see this.
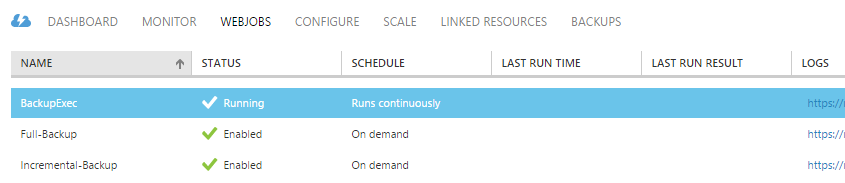
After it deploys we can test it. Throw some files in the “images” and “stuff” containers you created earlier in the “source” storage account. Next click on “Run Once” at the bottom of the Management Portal screen, then click on the URL for the “Full-Backup” in the LOGS column. In a moment you should see a screen like this.
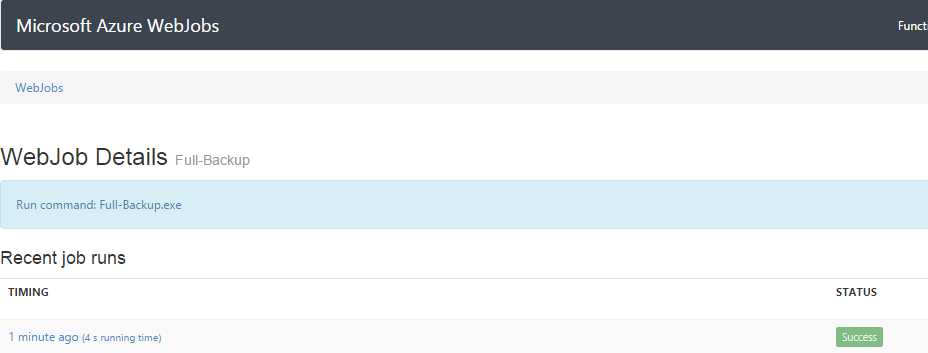
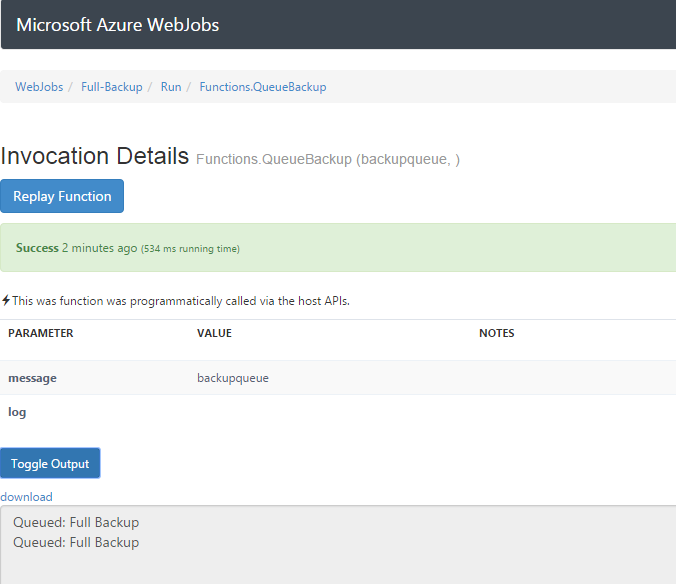
Click on the hyperlinked function under “Recent job runs” and then click, “Toggle Output” and you should see two messages. Those were created when we used the log.writeline() in the Full-Backup job.
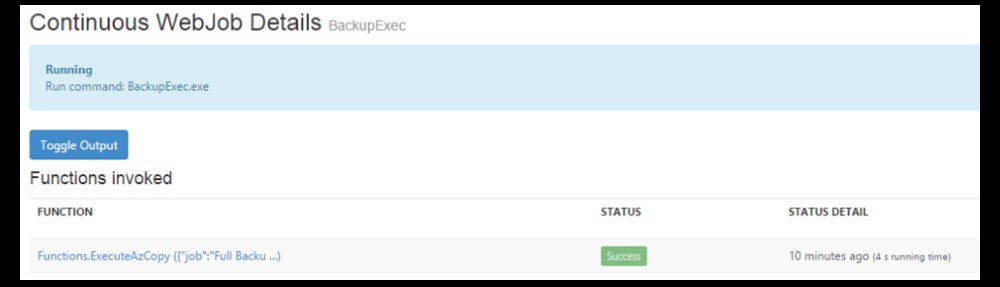
Next, go back to the Management Portal. Then click on the log URL for the BackupExec WebJob. You should see this.
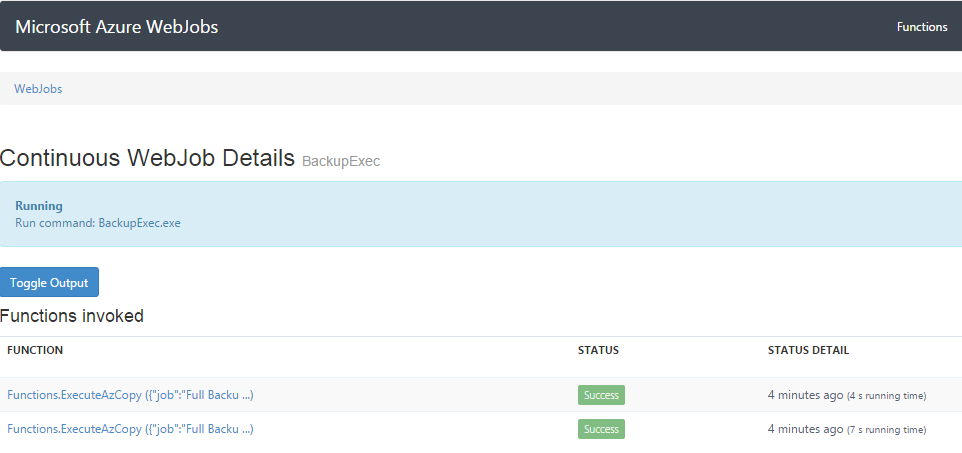
Click on either of the hyper-linked items under “functions included” and then, Toggle Output and you should see this.
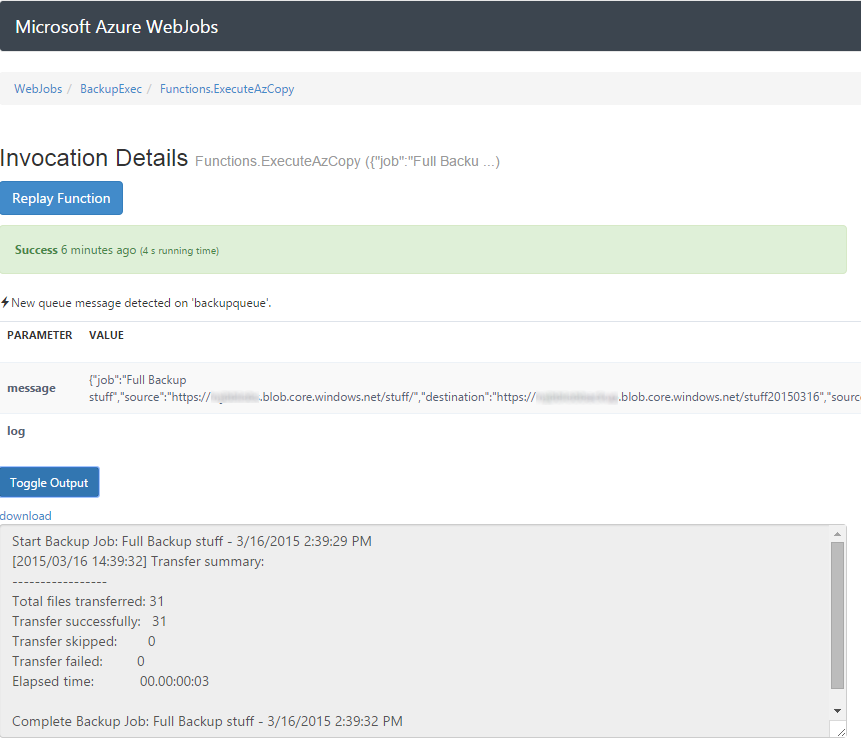
There’s a lot of data inside this job. At the top there is the name of the job and the time it started. That’s from our use of log.WriteLine() at the beginning of the ExecuteAzCopy() in the BackupExec WebJob. Next is the standard output generated by AzCopy.exe, then finally our last log.WriteLine() that shows the completion of the task.
So that’s basically it. I realize this was a long blog post. I’ve put this project up on GitHub, AzCopyBackup so you can get the code and then just follow along. Hope you enjoyed this and hope you find it useful.
Just wanted to let you know that I appreciate this end-to-end post — it was not too long, just right 🙂
very helpful.
Hi Mark, great blog. Found it extremely helpful.
Did you find there was much a cost incurred as a result of the setup you’ve outlined above? E.g. VMs setup, CPU time for the copying etc?
I’m looking to solve a similar problem, though keeping all data in the same region, as apparently there is no cost incurred when copying data around, in the same region.
Hi Gavin. Some answers to your questions.
There is hardly any cost associated with this type of solution. I run this for a client and use it to copy about 80GB of blobs across three storage accounts. I do it using a single Small Basic instance that costs ~ $55/month and it takes about 3 hours to complete. If I scale up to a large instance the job completes in about 2 hours. Frankly its not worth the cost to run it on anything larger than a small.
Now you can definitely scale out and run in multiple VM’s. However this is a bit tricky. If you try to copy into the same container from two different processes you will run into some write contention which can slow down the entire copy operation. The way to successfully do a scale out is to ensure you are writing to different containers. This gets a bit tricky since you now need to maintain state on what containers are currently being written to. I plan on creating an update to this app that does just that in a future version. But its something you can do yourself with a little bit of effort by creating another queue in the WebJobs storage account and using it to maintain state.
Hope that helps.
Mark
Hi,
I’m attempting to use what you’ve done above (which works for blob store) with a table store. Everything appears to work the webjob shows success but with no information and there’s no output.
I basically only changed the parameters that are sent to azcopy. Is there some other code I need to change to get this to work with table store?
I found my issue – I was missing the System.Spatial dll. The error message wasn’t being passed up either which was annoying.
Mark, your desires have been answered 😉
https://azure.microsoft.com/en-us/blog/introducing-azure-storage-data-movement-library-preview-2/
Really nice article. I don’t get why the incremental backup is necessary. It’s essentially the same as the full backup in as much as it simply copies the directory again. An incremental backup should be changed files since the last backup. Is there any easy way to achieve this?
The full backup (if you don’t specify /XO) will copy (recopy) every file. Incremental copy only copies newer files so it is much faster than doing a Full Copy again.
Hope that explains it better.
Great article!
Love to see an update of it now that AzCopy 5 has been released which also can copy tables.
Eventually got this working, but had to change your code because there are several mistakes. First of all, the AzCopy parameters need to be capitalized properly or else it won’t run at all and will give no errors: /Source, /Dest, /SourceKey, and /DestKey, to be specific. Also you oversimplify the AzCopy .dlls copy step, it is necessary to jump through some hoops to get these dlls on the server without borking the deploy because these may be different versions than the one in the app’s package restore, so they end up overwriting them and killing the web app.
Pingback: Automating Backups with WebJobs and Data Movement Library | mark j brown
Thanks for this post. I have been looking at a way to schedule AzCopy.
The problem I have at the moment is that if I run a scheduled task with AzCopy, at some point (an hour, maybe less) the logs start filling up with errors such as :
The remote server returned an error: (412) The condition specified using HTTP conditional header(s) is not met..
I then have to run the AzCopy without the /Y flag and then press Y interactively.
Once done, the scheduled task runs a bit longer.
I think it’s something to do with this journal that azcopy keeps for tracking it’s progress. Seems it doesn’t update the journal when run in the console?
Wondering why you never ran into that problem?
Great article, thanks.
You might be able to achieve the same thing now with Azure Functions instead of having to spin up a whole WebSite. https://azure.microsoft.com/en-us/documentation/articles/functions-overview/
Rory
Hi just discovered this article! Is it possible to do a point-in-time restore to a certain day using this system? What I mean is, since the backup is incremental it contains all files backed up since the full backup so how do you know which of the files were in the original storage on a particular day?
Since this creates a new container to store files you could write a storage client application which traverses the backup containers and then traverses the files within them to build a file dictionary or sorts.
You could also make this a little easier by simultaneously creating an index of files copied and saving that in the root of the container. Kind of like an index.dat file.