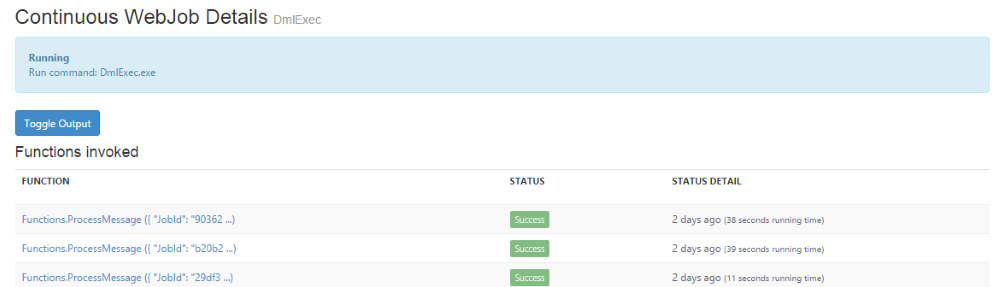
This post is an update to a post and app I wrote last Summer, Automating Backups with Azure WebJobs and AzCopy.
In this post I will show you how you can combine Azure WebJobs with the Data Movement Library to build your own scheduled storage backup or copy service for blobs.
Get the source for this blog post here, AzureDmlBackup.
Credits
Before we start I want to call out and thank Pranav Rastogi, and Longwen Lu who reviewed this application, provided some key insights into WebJobs and DML.
What is the Data Movement Library
The Data Movement Library for .NET (DML) is a library that based on core of the popular AzCopy utility created by the same team. With DML you can write fully managed applications with the power of AzCopy and with the ability to highly customize how it works. Currently DML supports Azure Blobs and Files. You add DML to your project via nuget. The source for DML is on GitHub and there is also a helpful repo of DML samples too.
Azure WebJobs
If you are not familiar with Azure WebJobs you should stop reading this, drop everything and go check them out right now. It’s ok, I’ll wait…. Azure WebJobs is a framework for running background tasks. You can trigger a job to run on a schedule, from a queue message, a new blob object, or a through pretty much anything using WebJobs Extensions. In short, WebJobs are amazing and extremely flexible.
The WebJobs team works at a pretty fast clip and are constantly updating and adding new features to it. Many of the newer features are brought about via the Extensions SDK I just mentioned. They also have support for multiple means to scheduling them including cron.
Exploring AzureDMLBackup
Let’s walk through the app, explaining some of the pieces.
Project Structure
If you’re familiar with the AzCopy & WebJobs app I built last year, the solution structure here should look familiar. There are three WebJob projects (Full, Incremental, DmlExec), a project (Shared) with a single shared class, and a host Web App project (AzureDmlBackup) which the WebJobs are deployed into.
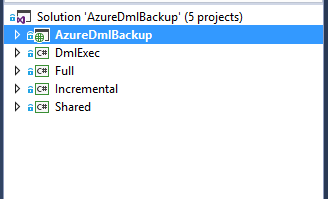
Full and Incremental Projects
The Full and Incremental WebJobs are very simple. They write messages onto a queue that describes what to copy. The projects are nearly identical but different in two key areas. The Full project includes a flag “IsIncremental” that is set to false. When it is false the DmlExec will always overwrite the destination file. If is is true, DmlExec will check to see if the source is newer. If it is, it will overwrite it, otherwise it skips it.
The other reason there are two projects and not one is Full is run on-demand and Incremental is run on a schedule using a settings.job file. Incremental is scheduled to run every Monday – Thursday at 23:30 UTC (everything in Azure is on UTC time). WebJobs now support multiple ways to trigger them via a schedule. Read more on WebJobs scheduling capabilities at TimerTriggers.
The Full and Incremental projects use “tokens” to identify the source and destination Azure storage accounts from which to copy. The tokens are stored in the Connection Strings of the host Web App in the Azure Portal.
Within either project you define your source and destination accounts, then repeatedly call the CreateJob() function passing a container you want to copy. I do this for three reasons.
- It is easier to update the connection strings in the portal rather than redeploying the application.
- They are or can be shared across Full and Incremental so rather than putting them twice in each project’s app.config I put them in a single location.
- I did not want to leak secrets using a queue. A queue can be secure but it seems an unnecessary risk if one storage account is compromised then others would be as well. By using tokens it reduces a potential vector.
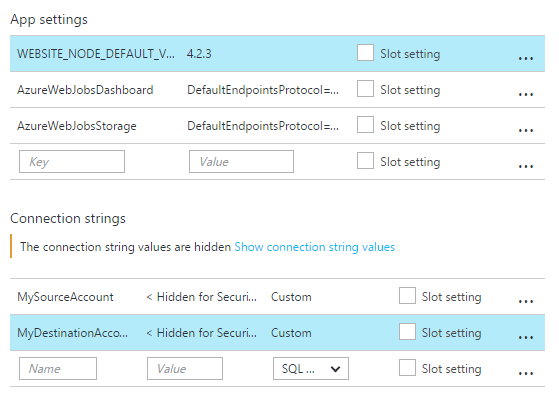
DmlExec Project
The DmlExec is the other main project in this solution and where we will spend the rest of this blog post. This project is a continuously running WebJob. It listens to a queue to read and process new messages created by the Full or Incremental WebJobs. There are a number of classes in this project besides the normal Program and Functions classes for WebJobs.
This solution uses the logging feature in WebJobs extensively. To keep the code cleaner, the code for logging is in a helper class, Logger. There is also a class called, TransferDetail. This is used to collect errors on individual blobs during copy operations. After the job is complete the Logger class writes its contents to the WebJobs log if there are any files which were skipped or that failed. Lastly, there is a class called ProgressRecorder. This class is used by DML to collect data on the files that are copied successfully, skipped or failed. It also times the entire copy operation. When the job is complete its contents are written to the WebJobs log.
Performance Tuning
The DML has a number of settings you can tweak to improve performance of the copy operations. I did a large amount of testing to confirm the settings I used in this solution. The Azure Storage team was also very helpful in understanding what the optimal settings were for DML.
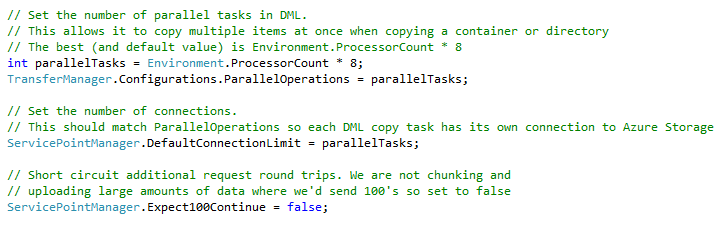
ParallelOperations
ParallelOperations tells DML how many worker threads to use when copying. For the CopyDirectoryAsync() function this solutions uses, the parallel operations are the ones copying blobs from one storage account to another. From the Azure Storage Team:
We use a producer-consumer pattern to list and transfer blobs. Basically, there are two threads: One lists blobs from the source container and add them into a blocking queue. This thread will be blocked if the queue reaches its size limitation. Another thread get blobs out of the queue and start a worker thread to copy the blob. This thread maintains a counter of the outstanding workers and block itself for a while if it reaches the parallel limitation.
I tested a number of values for this setting. What I found (and confirmed by the Azure Storage Team) was the optimal value for this is 8 parallel operations per processor. If you want to increase the number of copy operations over a period of time, the best way is to scale up the size of your VM so have more processors. Performance will increase at a near linear rate.
DefaultConnectionLimit
Another setting that goes hand in hand with ParallelOperations is DefaultConnectionLimit for the ServicePointManager. This setting limits the number of connections your application has and its value should match the number of parallel operations. If you think about it, this makes perfect sense. If you have more worker threads than connections the workers are going to sit and wait for a connection to become available. If you have more connections than workers then you are not allocating all available resources to copy blobs. By making them the same then each thread gets its own connection to Azure Storage and you get the most efficient use of resources.
IsServiceCopy
IsServiceCopy is a parameter that is set when calling one of the “Azure to Azure” copy functions in DML. CopyBlobAsync(), CopyDirectoryAsync(), etc. When this value is true the copy will be offloaded and executed completely server side in Azure. When it is false the copy is executed locally. It may seem tempting to set this to true all the time however there are some trade-offs when doing this. If this value is set to true, the copy is executed using available bandwidth. In some cases this may result in much slower performance than if you had set the value to false. Important to know that when this value is true, there is no SLA on your storage access.
I tested this extensively and in my opinion you are better off to set this value to false and copy the blobs using local resources and connections. The performance is more predictable and you will get bandwidth and performance up to the quota limits for the Storage Service.
TransferContext and TransferCheckpoint
The TransferContext is the context object for the the copy operation. It is used to get information about its execution. It also provides a delegate which is called by DML when it encounters an overwrite during the copy. Lastly it provides three event handlers that are called as each file is copied between two storage accounts.
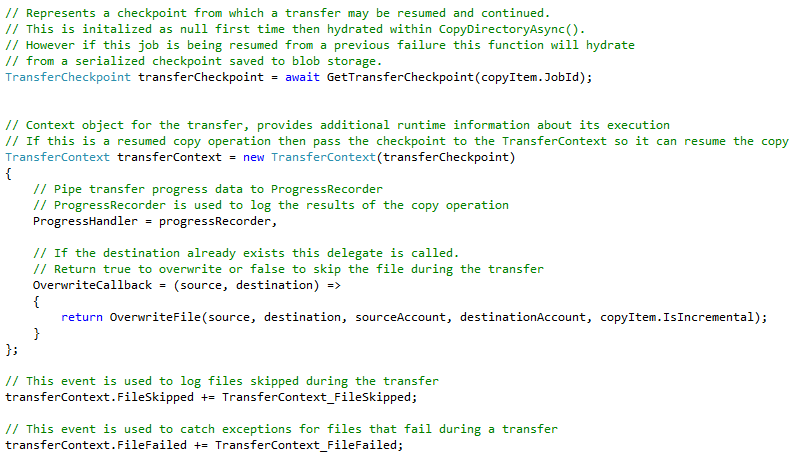
ProgressHandler
ProgressHandler is a delegate that can be used to capture information about the copy operation including bytes transferred, number of files transferred, skipped, or failed. You can see the example provided by the Storage Team in their DML Samples repo. I wanted to get performance metrics for my solution so I also included a start and end time in my implementation and then emit an Elapsed Time in the ToString() override.
OverwriteCallback
OverwriteCallback is a delegate that is called by DML when it encounters a file to overwrite during a copy operation. The delegate provides a source and destination parameters which are the URI’s to their respective objects to copy. The delegate accepts a true or false in return. Setting it to true will overwrite the file. Setting it to false will skip the file.
In my implementation, when IsIncremental is set to true, I use this delegate to check whether the source file is newer than the destination. If it is newer I return true and the destination is overwritten. If it is not, then I return false and the file copy is skipped. When IsIncremental is false I don’t check if the source is newer and just overwrite the file.
If you are copying a container or directory that you have already copied before you can get some significant performance improvements by setting IsIncremental to true.
Because the OverwriteCallback is only called if the destination exists, you do not need to use the Full WebJob to copy a container for the first time, you can use the Incremental one if you want. There is no performance penalty. Only use Full if you need to force an overwrite.
Event Handlers
The TransferContext includes three event handlers, FileTransferred, FileSkipped and FileFailed. All three of these are called as each file is copied. This solution does not hook into FileTransferred as it represents files that were successfully copied.
FileSkipped is called when a file is skipped in the OverwriteCallback as discussed above. In this solution we catch this event and collect information on each file that is skipped and the reason for it. When a file is skipped via the OverwriteCallback the message is always going to be, “Destination already exists”. After the copy is complete the app checks to see if the List object that is collecting each of the skipped files has a count > 0, if it does it writes out its contents to the WebJobs log.
The last event is FileFailed and it is called when a file fails to copy. Just like in FileSkipped the file information and the exception message are collected in a List and then written it to the WebJobs log when the copy operation is complete.
However, there is more to this and to exception handling in general using DML. Let me explain
Exception Handling
Normally in an application you have a catch block that catches an exception and you handle it. However, with DML since the calls to it are long running operations that can span thousands of individual copy operations this approach does not work. There is also one other complicating factor.
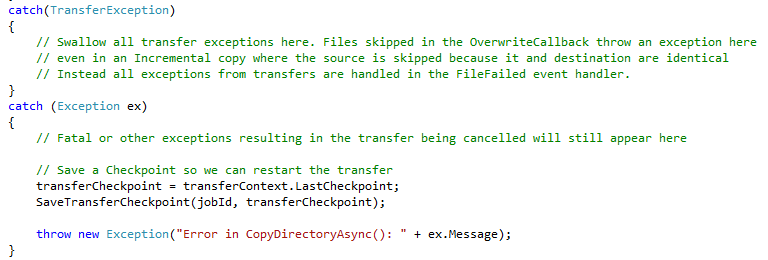
When an exception occurs in DML and a file fails to copy, DML does not stop the copy operation unless something fatal occurs and causes the entire job to be cancelled or failed. When a file fails DML raises a “TransferException”. If you call CopyDirectoryAsync and await it, the function will throw this TransferException. However if you want to log the files and their reasons for failing it is too late to do so. This is one reason why there is an event handler that is called for each individual file copy.
The other complicating factor in all this is that if you skip a file using the OverwriteCallback DML will also throw a TransferException. What’s more it will use the very same Transfer Error Code, SubTransferFailed. This makes catching and swallowing a skipped file impossible if you were looking to simply catch the TransferException.
The solution is to use the FileFailed event and set a flag which you then check after the copy is completed. This is precisely what I am doing in this code below.
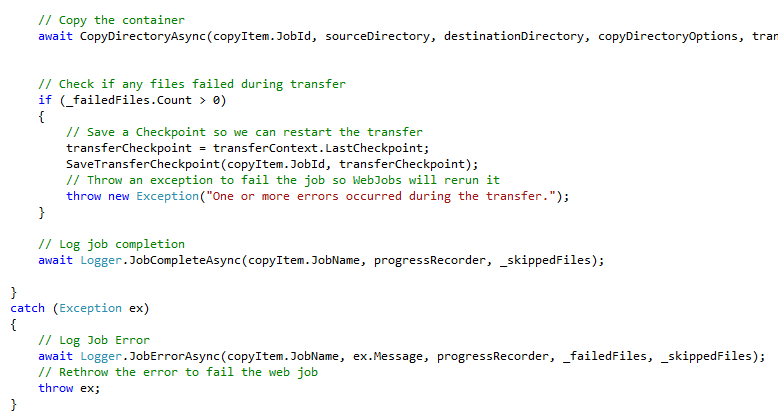
It also allows us to do something that is a really cool feature of DML, restarting copy jobs where they left off.
TransferCheckpoint
One of the coolest objects in DML is the TransferCheckpoint. The TransferCheckpoint hangs off the TransferContext and it provides a means for recording which files copied and which did not. Best of all, you can serialize this object and persist it to, say, blob storage, then by leveraging the WebJobs capability of rerunning a WebJob that fails you can retry the copy operation. But instead of retrying thousands of files all over again, you are only copying the files that failed the first time which is much more efficient and faster.
When one or more files fail to copy, the Checkpoint is stored in the WebJobs Storage Account in a container we create “dmlcheckpoints”. Each time a WebJob is run, it checks that container to see if there is a file with the same Job Id as the current WebJob. If there is, the app knows this invocation is a rerunning of a previously failed WebJob. It then retrieves the CheckPoint and hydrates the TransferContext through its constructor. From there DML handles the rest. Everything else is exactly the same.
Other things
There are a few other things that are interesting to point out with this application.
Transient Fault Handling
DML has built in transient fault handling for its own copy operations. However the app needs to access Azure Storage on its own behalf as well so this application implements transient fault handling on Azure Storage as well and uses it for all calls to Azure Storage it makes.
WebJobs Storage Connections
While WebJobs allows you the option of putting the AzureWebJobsDashboard and AzureWebJobsStorage account connection strings in many locations, this solution does not. The app is written to read these connection strings from the App Settings from the host web site.
Closing
So that’s it. I hope you enjoy playing with this solution and with WebJobs and DML in general. The source for this is here AzureDmlBackup.
Great article, Mark. Have you happened to think how this would port over to Service Fabric to get even wider scalability?
I’ve been debating WebJobs vs Service Fabric, both driven from a Azure Service Bus queue. Basically as a job processing system, where each message equals a job to run.
Thanks for writing this! I’m trying out your project, but when running the full backup I’m running into:
Microsoft.Azure.WebJobs.Host.FunctionInvocationException: Microsoft.Azure.WebJobs.Host.FunctionInvocationException: Exception while executing function: Functions.ProcessMessage —> System.Exception: Error in GetTransferCheckpoint(): Object reference not set to an instance of an object. at DmlExec.Functions.d__7.MoveNext() — End of stack trace from previous location where exception was thrown — at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task) at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task) at Microsoft.Azure.WebJobs.Host.Executors.FunctionInvoker`1.d__0.MoveNext() — End of stack trace from previous location where exception was thrown — at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task) at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task) at Microsoft.Azure.WebJobs.Host.Executors.FunctionExecutor.d__31.MoveNext() — End of stack trace from previous location where exception was thrown — at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task) at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task) at Microsoft.Azure.WebJobs.Host.Executors.FunctionExecutor.d__2c.MoveNext() — End of stack trace from previous location where exception was thrown — at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task) at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task) at System.Runtime.CompilerServices.TaskAwaiter.ValidateEnd(Task task) at Microsoft.Azure.WebJobs.Host.Executors.FunctionExecutor.d__13.MoveNext() — End of inner exception stack trace — at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw() at Microsoft.Azure.WebJobs.Host.Executors.FunctionExecutor.d__13.MoveNext() — End of stack trace from previous location where exception was thrown — at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess(Task task) at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification(Task task) at Microsoft.Azure.WebJobs.Host.Executors.FunctionExecutor.d__1.MoveNext()
Any ideas?
Well, for some reason this is working all of a sudden…don’t ask me why!
Is there any straightforward solution for tables? I believe they’re not supported yet so I guess it’s just a matter of manually retrieving all table entities and creating a JSON file or new table from them.
Hi Sam. Sorry for not responding sooner. Tables are not supported and I don’t see them coming anytime soon. You can definitely ask for it though here, https://github.com/Azure/azure-storage-net-data-movement/issues